
PyTorch AMP Mechanism
Automatic mixed precision(AMP) 自动混合精度训练与推理,自动决定哪些算子以float16运行,哪些以float32运行,从而在降低内存以及带宽,提高计算性能的同时,减少精度损失。
背景
硬件
Nvidia 在 Volta 架构中首次引入 Tensor Core 单元,来支持 FP32 和 FP16 混合精度计算
FMA: Fused Multiply-Add 的操作,通俗一点就是一个加乘操作的融合
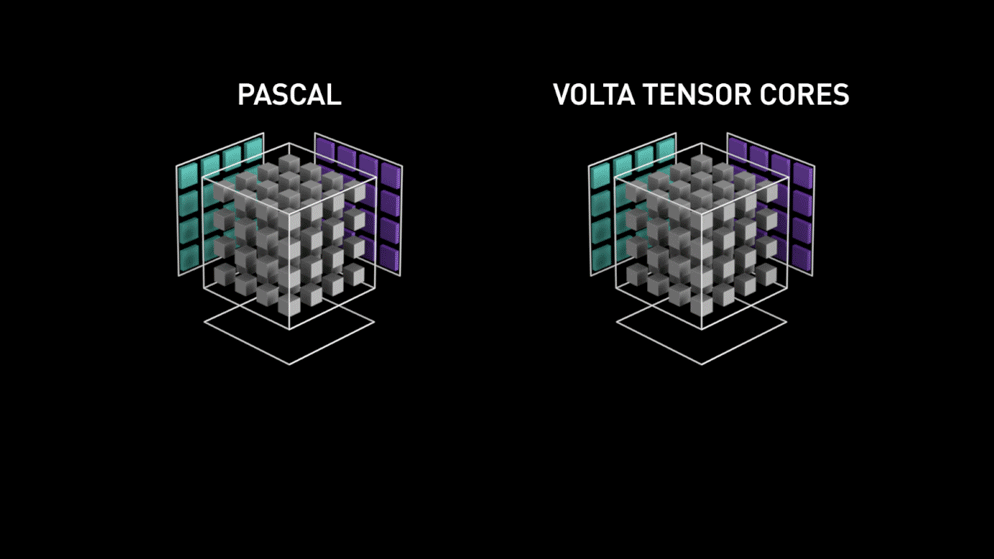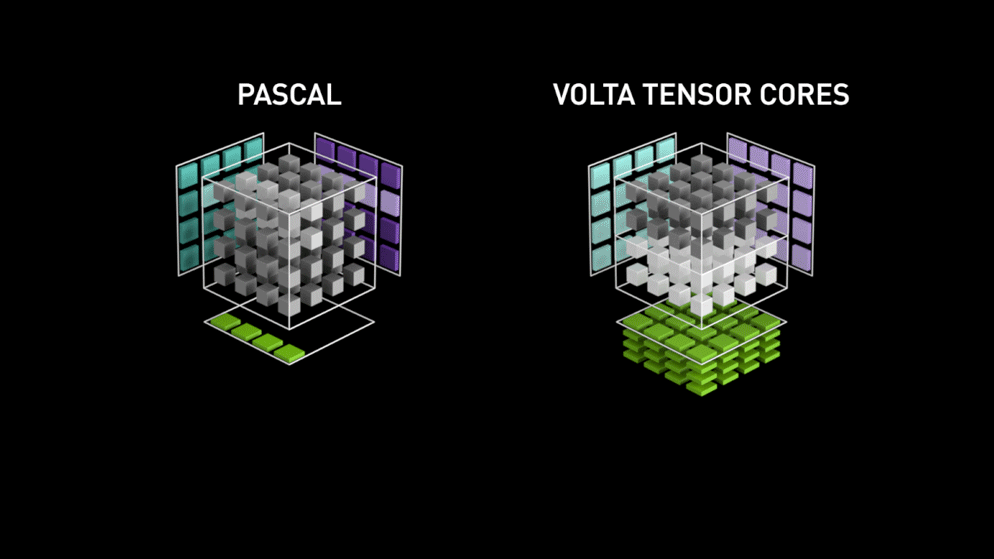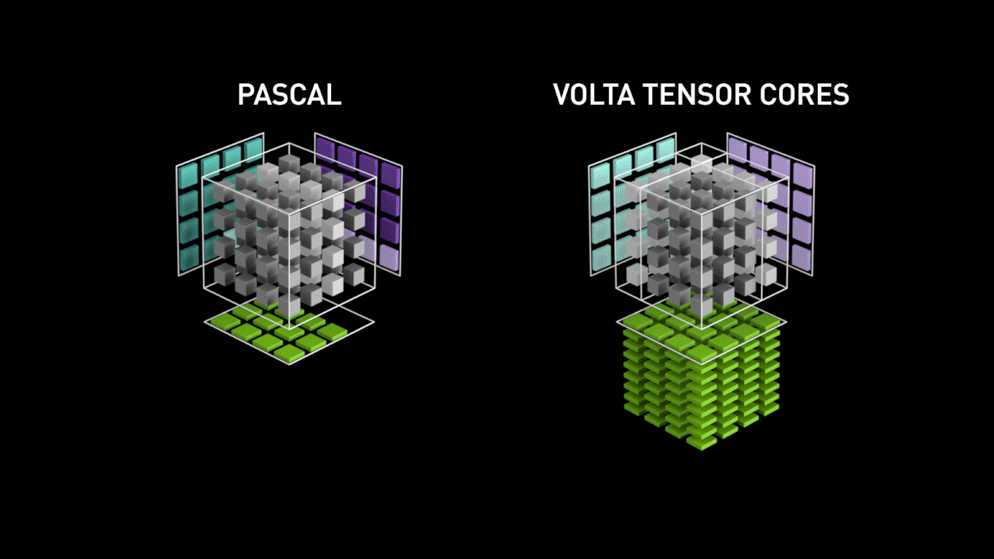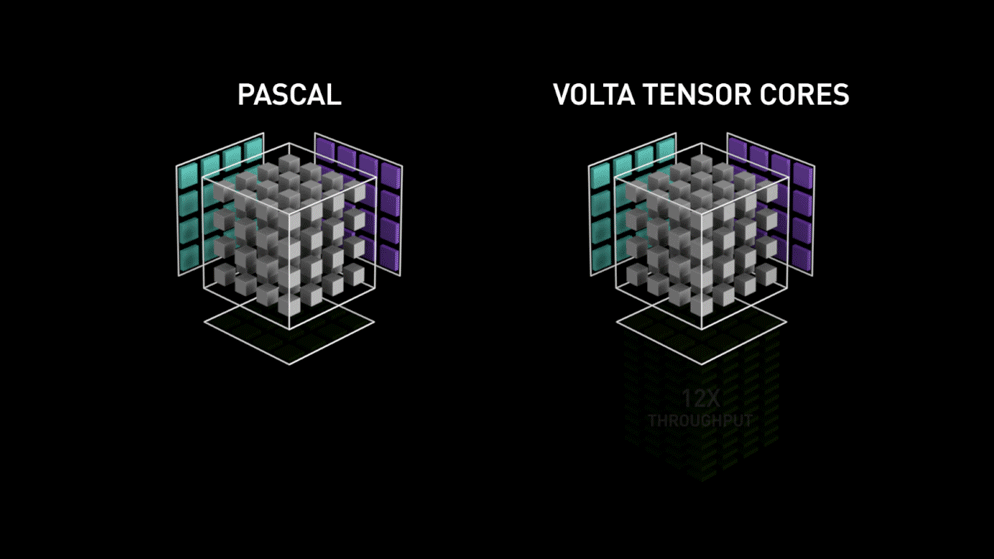
Cuda Core:
Cuda Core是全能通用型的浮点运算单元,单GPU时钟周期完成一次FMA操作。
Tensor Core:
Tensor Core是专为执行深度学习矩阵运算而设计的专用执行单元,单GPU时钟周期完成一次矩阵相乘(以 4 * 4矩阵为例,单GPU时钟周期可以完成64次 FMA)

每一代Tensor Core支持的计算类型如下:
模型
Transform模型以及传统CNN模型等充斥着大量矩阵乘加运算
前世今生
Nvidia apex项目
为了释放Tensor Core的巨大性能,Nvidia 于 2018 年提出一个 PyTorch 拓展 apex,来支持模型参数自动混合精度训练和推理,用户只需要安装该插件(PyTorch 1.6之前)便可以使用Tensor Core的能力,该仓库只要包括以下几个特性:
- Amp: Automatic Mixed Precision
- Distributed Training(like DDP)
- Synchronized Batch Normalization(like torch.nn.SyncBN)
- Checkpointing(like checkpoint in PyTorch, for inference or resuming training)
PyTorch 1.6 内部集成 amp
2019年,Nvidia 在PyTorch 提交了一个 Feature Discussion,主要目的是想将apex的能力集成到PyTorch社区,也就是现在的torch.cuda.amp模块,基于的主要原因就是方便用户使用以及其真实的性能提升,最终跟随PyTorch 1.6版本原生发布。
用法
1 | # encoding: UTF-8 |
设计与实现
基于 Dispatcher 的注册以及分发(autocast)

TLS中的DispatchKeySet中插入Autocast Key
1 | ... |

前向forward开始
1 | ... |

Autocast 的CUDA实现(lower_precision_fp)
1 | template < |
防止 autocast 无限递归
1 | c10::impl::ExcludeDispatchKeyGuard no_autocast( |

转向后续处理(autograd, 算子真实的cuda实现)

如何解决float16自身精度引入的溢出问题?

Float16 表示的范围较窄,大量非 0 梯度会遇到溢出问题。
梯度缩放(GradScaler)

解决方法:
在反向传播之前,给loss乘以一个scaler factor,将会导致反向传播中的每个grad都乘以了相同的scaler factor,变相增加了float16可表示小数的范围,从而解决float16精度丢失的问题。
相关代码如下所示:
1 | scaler.scale(loss).backward() |
1 | scaler.scale(loss).backward() |
将loss乘以一个默认的scaler factor,然后按照正常流程反向传播,生成每个grad
1 | scaler.step(optimizer) |
将每个grad都除以scaler factor,进行梯度还原,同时记录梯度还原过程中是否存在inf/nan情况
- 如果存在inf/nan,本次迭代参数将不更新
- 如果不存在inf/nan,本次迭代参数将正不更新
1 | scaler.scale(loss).backward() |
根据上一步是否存在inf/nan的情况,动态调整scaler factor(每隔 _growth_interval 个 迭代周期)
- 如果存在inf/nan,scaler factor 乘以 一个小于1的系数 _growth_factor
- 如果不存在inf/nan,scaler factor 乘以 一个大于1的系数 _backoff_factor
以上三个参数均有默认值,也可以在初始化 GradScaler 时自行设置
QA
AMP 是否依赖 Tensor Core
不依赖,不支持 Tensor Core的GPU也可以使用 AMP,内存会有降低,但是计算性能不保证
AMP 复制两份参数,为什么还能降低存储
PyTorch 模型训练时主要的内存占用大体分为以下几个方面:
- 模型参数:包括权重以及输入
- 优化器: Adam优化器 (momentum,variance)/Per Grad,其他优化器类似
- AMP: 复制 float16 输入以及权重
- 激活值:计算中间值,用来为backward做准备
- 梯度:每个参数的梯度值
其中,第三项会增加内存使用(每个参数新增两字节消耗),而第4,5项由于以半精度存储(相对于单精度,激活值和权重加起来减少了4字节消耗)